Reconoce una foto, una canción, el hábito de un usuario. Con inteligencia artificial ya es posible. Pero, ¿por qué es importante y cómo está afectando nuestra forma de vida?
Antes de responder a esta pregunta, debemos dar un paso atrás para explicar la diferencia entre Inteligencia artificial (AL), Aprendizaje automático (Machine learning & LLM) (ML) y Aprendizaje profundo (DL), términos que muchas veces se confunden pero con un significado preciso.
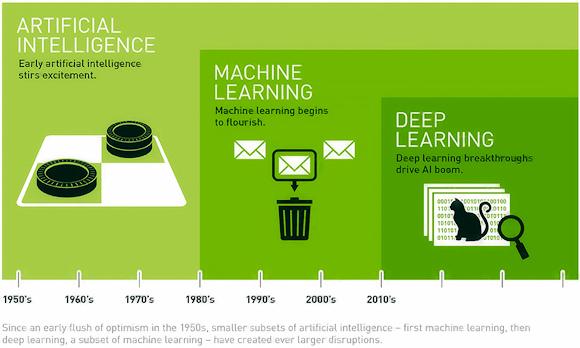
Para explicar la idea básica, usemos una imagen (apertura) tomada del sitio web de NVIDIA.
De la imagen se desprende que la noción de AI es un concepto general de ML que a su vez es un concepto más general de DL. Pero no solo. De hecho, como vemos los primeros algoritmos de deep learning nacieron hace poco más de 10 años a diferencia de la inteligencia artificial que nació alrededor de los años 50 con los primeros lenguajes como LISP y PROLOG con el objetivo de imitar las capacidades de la inteligencia humana.
Los primeros algoritmos de inteligencia artificial se limitaban a realizar un determinado número de acciones posibles según una determinada lógica definida por el programador (como en el juego de las damas o el ajedrez).
a través de la máquina de aprendizaje, la inteligencia artificial ha evolucionado a través de los llamados algoritmos de aprendizaje supervisado y no supervisado con el objetivo de crear modelos matemáticos de aprendizaje automático basados en una gran cantidad de datos de entrada que constituyen la "experiencia" de la inteligencia artificial.
En el aprendizaje supervisado, para crear el modelo, es necesario entrenar la IA asignando una etiqueta a cada elemento: por ejemplo, si quiero clasificar frutas, tomaré fotografías de muchas manzanas diferentes y etiquetaré el modelo como "manzana". así que para pera, plátano, etc.
En el aprendizaje no supervisado el proceso será al revés: habrá que crear un modelo a partir de diferentes imágenes de frutas, y el modelo tendrá que extraer las etiquetas según las características que tienen en común manzanas, peras y plátanos.
Los modelos de máquina de aprendizaje supervisados ya son utilizados por antivirus, filtros de spam, pero también en el campo de marketing como los productos sugeridos por amazon.
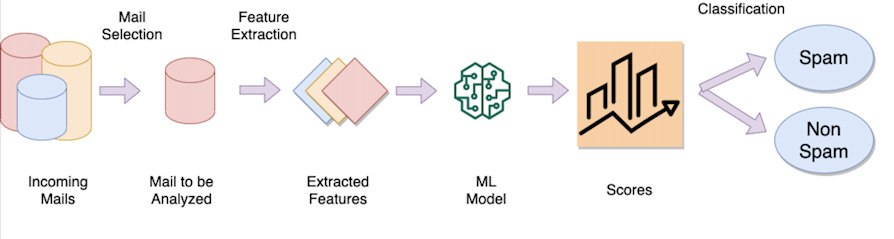
El ejemplo del filtro de spam
La idea detrás de un filtro de spam de correo electrónico es entrenar un modelo que "aprende" de cientos de miles (si no millones) de correos electrónicos, etiquetando cada correo electrónico como correo no deseado (spam) o legítimo. Una vez entrenado el modelo, la operación de clasificación implica:
Extracción de características peculiares (llamadas características) como, por ejemplo, las palabras del texto, el remitente del correo electrónico, la dirección IP de origen, etc.
Considere un "peso" para cada característica extraída (por ejemplo, si hay 1000 palabras en el texto, algunas de ellas pueden ser más discriminatorias que otras, como la palabra "viagra", "pornografía", etc. tendrán un peso diferente que buenos días, universidades, etc.)
Ejecutar una función matemática, que tomando como características de entrada (palabras, remitente, etc.) y sus respectivos pesos, devuelva un valor numérico
Compruebe si este valor está por encima o por debajo de un cierto umbral para determinar si el correo electrónico es legítimo o se considera spam (clasificación).
Neuronas artificiales
Como dije, el Aprendizaje profundo es una rama de la máquina de aprendizaje. la diferencia con máquina de aprendizaje es la complejidad computacional lo que pone en juego grandes cantidades de datos con una estructura de aprendizaje "en capas" hecha de redes neuronales artificiales. Para entender este concepto, partimos de la idea de replicar la única neurona humana como en la figura a continuación.
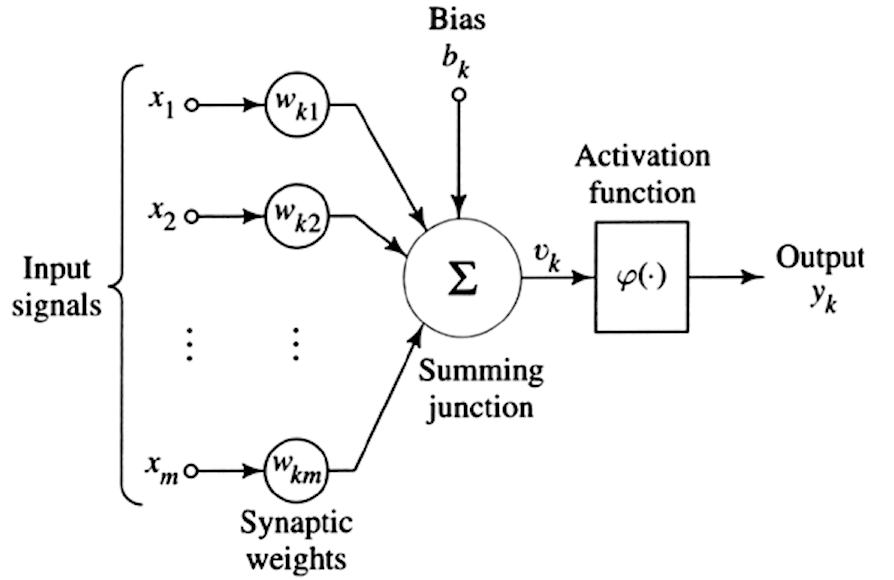
Como se vio anteriormente para el aprendizaje automático, tenemos una serie de señales de entrada (a la izquierda de la imagen) a las que asociamos diferentes pesos (Wk), agregamos un "sesgo" cognitivo (bk) que es una especie de distorsión, y finalmente aplicamos una función de activación, es decir, una función matemática como una función sigmoidea, tangente hiperbólica, ReLU, etc. que tomando una serie de entradas ponderadas y teniendo en cuenta un sesgo, devuelve una salida (yk).
Esta es la única neurona artificial. Para crear una red neuronal, las salidas de una sola neurona se conectan a una de las entradas de la siguiente neurona, formando una densa red de conexiones, como se muestra en la siguiente figura, que representa la red real. Red neuronal profunda.
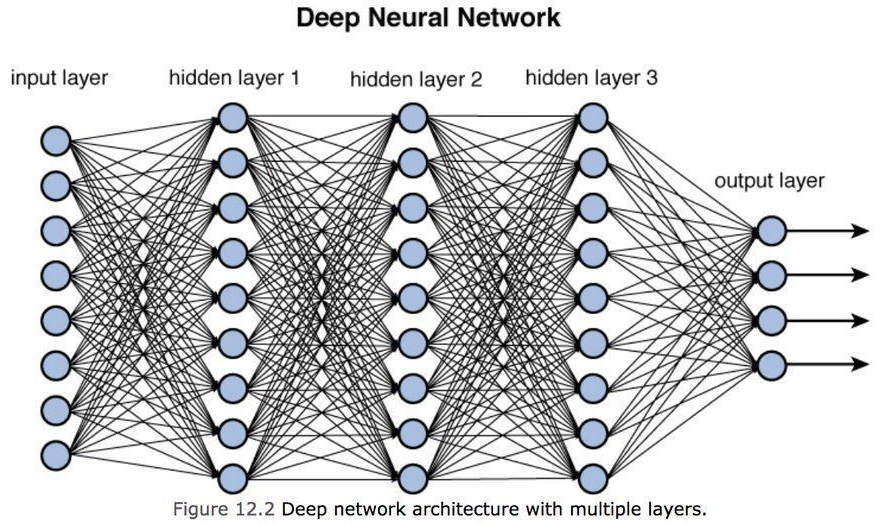
Aprendizaje profundo
Como podemos ver en la figura anterior, tenemos un conjunto de entradas para suministrar a la red neuronal (capa de entrada), luego niveles intermedios llamados capas ocultas que representan las "capas" del modelo y finalmente un nivel de salida capaz de discriminar ( o reconocer) un objeto sobre otro. Podemos pensar en cada capa oculta como una capacidad de aprendizaje: cuanto mayor sea el número de capas intermedias (es decir, cuanto más profundo sea el modelo), más precisa será la comprensión pero también más complejos serán los cálculos a realizar.
Tenga en cuenta que la capa de salida representa un conjunto de valores de salida con un cierto grado de probabilidad, por ejemplo, 95 % una manzana, 4,9 % una pera y 0,1 % una banana, etc.
Imaginemos un modelo DL en el campo de visión de computadora: la primera capa es capaz de reconocer los bordes del objeto, la segunda capa a partir de los bordes puede reconocer las formas, la tercera capa a partir de las formas puede reconocer objetos complejos compuestos de varias formas, la cuarta capa a partir de formas complejas puede reconocer detalles y así sucesivamente. Al definir un modelo no hay un número preciso de capa oculta, pero el límite lo impone la potencia necesaria para entrenar al modelo en un tiempo determinado.
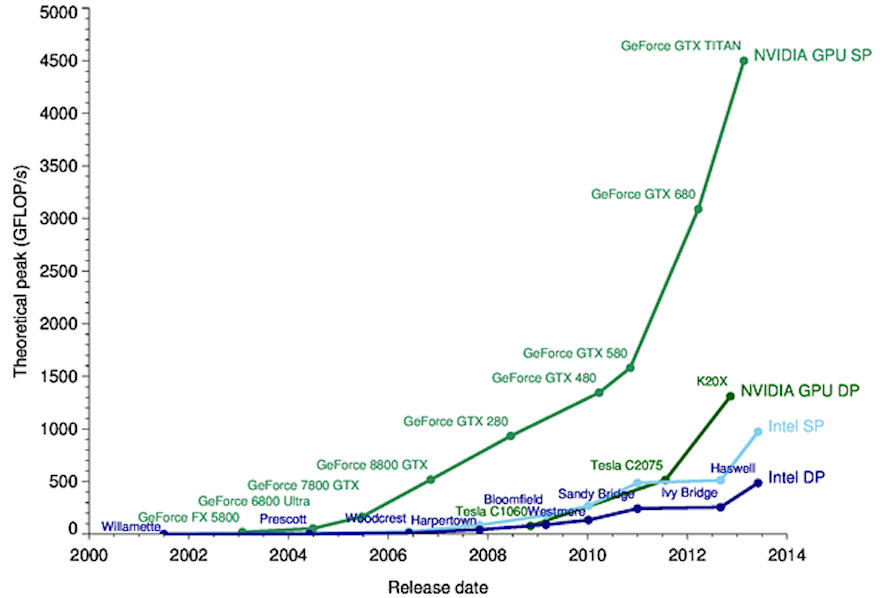
Sin entrar en demasiados detalles, el entrenamiento de una red neuronal tiene como objetivo el cálculo de todos los pesos y sesgos que se aplicarán a todas las neuronas individuales presentes en el modelo: por lo tanto, es evidente que la complejidad aumenta exponencialmente a medida que el intermedio aumentan las capas (capa oculta). Por esta razón, se han utilizado procesadores de tarjetas gráficas (GPU) para la la formación: estas tarjetas son adecuadas para cargas de trabajo más exigentes ya que, a diferencia de las CPU, pueden realizar miles de operaciones en paralelo utilizando arquitecturas SIMD (Single Instruction Multiple Data) y tecnologías modernas como Núcleo tensor que permiten operaciones matriciales en hardware.
Aplicaciones de aprendizaje profundo
Al procesar grandes cantidades de datos, estos modelos tienen una alta tolerancia a fallas y ruido a pesar de los datos incompletos o inexactos. Por lo tanto, proporcionan un apoyo fundamental en todos los campos de la ciencia. Veamos algunos de ellos.
Clasificación de imágenes y seguridad
En caso de delitos, permite el reconocimiento de un rostro a partir de la imagen captada por una cámara de vigilancia y comparándola con una base de datos de millones de rostros: esta operación, si la realiza manualmente el hombre, puede demorar días, si no meses o incluso años. Además, mediante la reconstrucción de imágenes algunos modelos permiten colorear partes faltantes de las mismas, con una precisión ahora cercana al 100% del color original.
Procesamiento natural del lenguaje
La capacidad de una computadora para comprender textos escritos y hablados de la misma manera que lo harían los humanos. Entre los sistemas más famosos, Alexa y Siri son capaces no solo de entender sino de responder preguntas de diferente naturaleza.
Otros modelos son capaces de hacer análisis de los sentimientos, utilizando siempre sistemas de extracción y opiniones del texto o de las palabras.
Diagnósticos médicos
En el campo de la medicina, estos modelos ahora se utilizan para realizar diagnósticos, incluido el análisis de tomografías computarizadas o resonancias magnéticas. Los resultados que en la capa de salida tienen una confianza del 90-95%, en algunos casos, pueden predecir una terapia para el paciente sin intervención humana. Capaces de trabajar las 24 horas del día, todos los días, también pueden brindar apoyo en la fase de triaje de pacientes, reduciendo significativamente los tiempos de espera en una sala de emergencias.
Guía autónoma
Los sistemas autónomos requieren un seguimiento continuo en tiempo real. Los modelos más avanzados prevén vehículos capaces de gestionar cualquier situación de conducción independientemente de un conductor cuya presencia a bordo no esté prevista, previendo la presencia únicamente de pasajeros transportados.
Pronósticos y elaboración de perfiles
Los modelos financieros de aprendizaje profundo nos permiten hacer hipótesis sobre las tendencias futuras del mercado o conocer el riesgo de insolvencia de una institución con más precisión de lo que los humanos pueden hacer hoy en día con entrevistas, estudios, cuestionarios y cálculos manuales.
Estos modelos utilizados en marketing nos permiten conocer los gustos de las personas para proponer nuevos productos, por ejemplo, a partir de asociaciones realizadas con otros usuarios que tienen un historial de compra similar.
Evoluciones adaptativas
Con base en las "experiencias" cargadas, el modelo puede adaptarse a situaciones que ocurren en el entorno o debido a la entrada del usuario. Los algoritmos adaptativos provocan una actualización de toda la red neuronal basada en nuevas interacciones con el modelo. Por ejemplo, imaginemos cómo Youtube ofrece vídeos de una determinada temática según la época, adaptándose día tras día y mes tras mes a nuestros nuevos gustos e intereses personales.
Finalmente, el Aprendizaje profundo es un campo de investigación aún en fuerte expansión. Las universidades también están actualizando sus programas de enseñanza en este tema que aún requiere una base sólida en matemáticas.
Las ventajas de aplicar el DL a la industria, la investigación, la salud y la vida cotidiana son indudables.
Sin embargo, no debemos olvidar que ésta debe servir de apoyo al hombre y que sólo en algunos casos limitados y muy específicos puede sustituir al hombre. Hasta la fecha, de hecho, no existen modelos de “propósito general” que sean capaces de resolver cualquier tipo de problema.
Otro aspecto es el uso de estas plantillas para fines ilegales como la creación de videos. Deepfake (ver artículo), es decir, técnicas utilizadas para superponer otras imágenes y videos con imágenes o videos originales con el objetivo de crear noticias falsas, estafas o pornografía vengativa.
Otra forma ilícita de usar estos modelos es crear una serie de técnicas destinadas a comprometer un sistema informático, como el aprendizaje automático antagónico. A través de estas técnicas es posible causar una clasificación incorrecta del modelo (y así inducir al modelo a hacer una elección incorrecta), obtener información sobre el conjunto de datos utilizado (introduciendo problemas de privacidad) o clonar el modelo (causando problemas de derechos de autor).
Referencias
https://blogs.nvidia.com/blog/2016/07/29/whats-difference-artificial-int...
https://it.wikipedia.org/wiki/Lisp
https://it.wikipedia.org/wiki/Prolog
https://it.wikipedia.org/wiki/Apprendimento_supervisionato
https://www.enjoyalgorithms.com/blog/email-spam-and-non-spam-filtering-u...
https://foresta.sisef.org/contents/?id=efor0349-0030098
https://towardsdatascience.com/training-deep-neural-networks-9fdb1964b964
https://hemprasad.wordpress.com/2013/07/18/cpu-vs-gpu-performance/
https://it.wikipedia.org/wiki/Analisi_del_sentiment
https://www.ai4business.it/intelligenza-artificiale/auto-a-guida-autonom...
https://www.linkedin.com/posts/andrea-piras-3a40554b_deepfake-leonardodi...










