¿Qué tal si fuera posible engañar a los compiladores para que produzcan binarios distintos de la lógica visible para los ojos humanos en el código fuente? Te mostramos que hacer esto no solo es posible, sino fácilmente explotable ...
Esto se afirma en la introducción del artículo. "Fuente del troyano: vulnerabilidades invisibles", publicado recientemente por el prof. Ross Anderson de la Universidad de Cambridge, autor del texto "Ingeniería de seguridad"y por Nicholas Boucher, su estudiante de doctorado.
Intrigados, como suele suceder en el mundo cibernético, decidimos profundizar ...
Para empezar, recuerde que los programas escritos con lenguajes de programación modernos necesitan un compilador, que es otro programa que analiza el texto de nuestro programa, verifica su corrección sintáctica y lo traduce a un programa optimizado en el lenguaje ejecutable por la computadora. Ya de esto entendemos la criticidad en el desarrollo de un compilador que podría insertar inadvertidamente vulnerabilidades en el programa.
En la década de 80 Ken Thomson, uno de los padres de Unix, ya advirtió de estos riesgos en su célebre conferencia pronunciada con motivo de la entrega del "premio Turing" (el equivalente al premio Nobel de informática) con el evocador título "Reflexiones sobre confiar en la confianza". El compilador del lenguaje C es en sí mismo un programa escrito en el lenguaje C, por lo que para poder confiar en el programa ejecutable producido por el compilador es necesario no solo confiar en quien escribió el programa, sino también en el compilador.
Ahora, volviendo al artículo de Boucher y Anderson, comencemos por considerar un compilador como un analizador de texto que conoce los términos y la sintaxis del lenguaje de programación. Los caracteres utilizados para formar el texto deben codificarse en una computadora.
Para entender en qué consiste este nuevo tipo de ataque presentado por Boucher y Anderson, primero debemos hablar sobre la codificación y los estándares utilizados para la codificación.
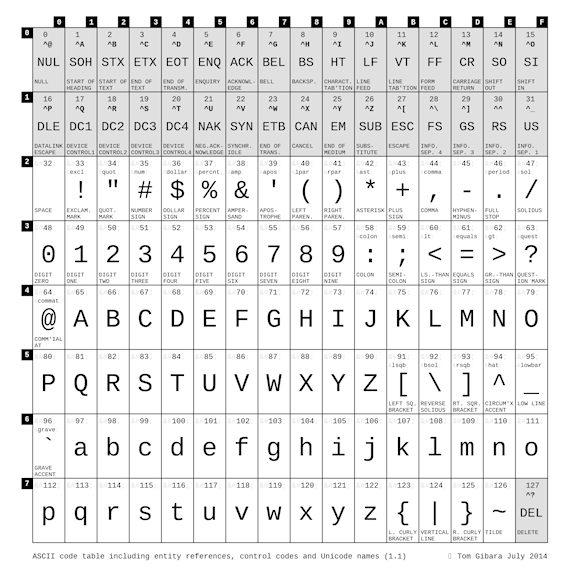
Uno de los estándares más utilizados en el mundo de la informática a lo largo del tiempo es ASCII, Código estándar estadounidense para el intercambio de información. La primera edición de esta norma se publicó en 1963 y se modificó varias veces a lo largo del tiempo. Se necesitaron siete bits para codificar 128 caracteres diferentes.
Con el desarrollo de los sistemas informáticos, las necesidades cambiaron y fue necesario extender el estándar ASCII para permitir la codificación de caracteres provenientes de diferentes idiomas o necesarios para entornos específicos.
El estándar conocido como UNICODE fue así aprobado gradualmente. Este estándar permite codificar 144.697 entre varios caracteres y símbolos. Entre estos se encuentran los llamados alfabetos De izquierda a derecha (de izquierda a derecha, como italiano, ruso, inglés ...) e De derecha a izquierda (de derecha a izquierda, como árabe, hebreo ...). En el caso de Unicode, que es uno de los estándares de codificación más utilizados en la actualidad, un algoritmo llamado Algoritmo bidireccional (Bi Di).
El algoritmo BiDi está diseñado para administrar automáticamente la visualización de texto a través de los llamados caracteres de control (caracteres de anulación) que le permiten especificar explícitamente cómo se debe tratar una parte específica del texto (por ejemplo Anulación de derecha a izquierda, RLO, especifica tratar el texto al que se aplica como De derecha a izquierda). Los caracteres de control son caracteres invisibles en la pantalla que le permiten controlar la visualización de partes de texto. Éstos son algunos de los más utilizados.

Además, los caracteres de control se pueden "anidar", lo que le permite reordenar la visualización de un texto de una manera muy compleja.
Ahora bien, si el texto que se muestra en pantalla es un código de programa, hay que tener en cuenta que, en principio, la sintaxis de la mayoría de los lenguajes de programación normalmente no permite insertar estos caracteres de control directamente en el código fuente de la forma en que obviamente alterarían mucho la lógica de control del programa. Sin embargo, dado que muchos lenguajes permiten el uso de comentarios y cadenas, es posible insertar caracteres de control dentro de comentarios o cadenas y hacer que tengan un impacto en el código fuente, ya que Ovverrides BiDi no respetan los delimitadores de cadenas y comentarios.
El tipo de ataque descrito por Boucher y Anderson se basa en esta característica típica de las codificaciones actuales. De hecho, gracias a los caracteres de control es posible aprovechar la diferencia entre lo que se muestra y lo que realmente se codifica y se pasa al compilador e intérprete para realizar el tipo de ataque "Trojan Source Attack" descrito por Boucher y Anderson.
Boucher y Anderson también demostraron que este tipo de ataque es posible con los lenguajes de programación más utilizados, incluidos C, C ++, C #, JavaScript, Java, Rust, Go y Python.
El siguiente ejemplo, en código Python, muestra que el código codificado (y por lo tanto ejecutado en la máquina) a la izquierda es diferente del código fuente (a la derecha) mostrado.

Con base en este último, uno esperaría encontrar un valor igual a 50 en el banco ['alice'] al final de la ejecución, mientras que en la práctica el valor presente seguirá siendo igual a 100.
El hecho de que hasta ahora no exista evidencia de este tipo de ataques no nos tranquiliza para el futuro ya que, como nosotros, otros pueden haber leído el periódico y, quizás, tomar la decisión de probar los conceptos.
Davide Ariu, Giorgio Giacinto y Alessandro Rugolo
Para obtener más información:
- Fuente del troyano: vulnerabilidades invisibles
- GitHub - nickboucher / trojan-source: Trojan Source: Invisible Vulnerabilities
- El algoritmo de texto bidireccional Unicode - Guías para desarrolladores | MDN (mozilla.org)